

Open sourcing MS-DOS 4.0
In partnership with IBM, we’re releasing the source code to MS-DOS 4.00 under the MIT license to support open innovation.

Watch our webinar on Open Data Science Conference
Read the white paper on SmartNoise Differential Privacy machine learning case studies
The COVID-19 pandemic demonstrates the tremendous importance of sufficient and relevant data for research, causal analysis, government action, and medical progress. However, for understandable data protection considerations, individuals and decision-makers are often very reluctant to share personal or sensitive data. To ensure sustainable progress, we need new practices that enable insights from personal data while reliably protecting individuals’ privacy.
Pioneered by Microsoft Research and their collaborators, differential privacy is the gold standard for protecting data in applications that prepare and publish statistical analyses. Differential privacy provides a mathematically measurable privacy guarantee to individuals by adding a carefully tuned amount of statistical noise to sensitive data or computations. It offers significantly higher privacy protection levels than commonly used disclosure limitation practices like data anonymization. The latter increasingly shows vulnerability to re-identification attacks—especially as more data about individuals become publicly available.
SmartNoise is jointly developed by Microsoft and Harvard’s Institute for Quantitative Social Science (IQSS) and the School of Engineering and Applied Sciences (SEAS) as part of the Open Differential Privacy (OpenDP) initiative. The platform’s initial version was released in May 2020 and comprises mechanisms for providing differentially private results to users of analytical queries to protect the underlying dataset. The SmartNoise system includes differentially private algorithms, techniques for managing privacy budgets for subsequent queries, and other capabilities.
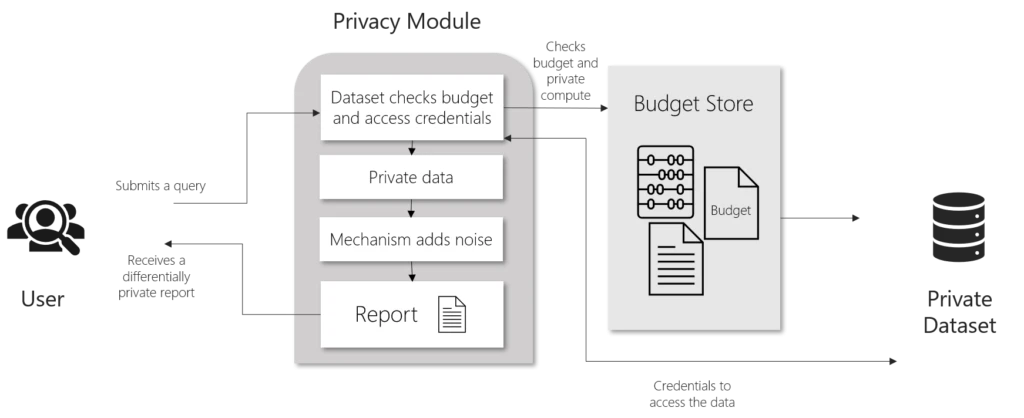
Check out the SmartNoise website to learn more. The code for the updated open source differential privacy platform is available on GitHub.
With the new release of SmartNoise, we are adding several synthesizers that allow creating differentially private datasets derived from unprotected data.
A differentially private synthetic dataset is generated from a statistical model based on the original dataset. The synthetic dataset represents a “fake” sample derived from the original data while retaining as many statistical characteristics as possible. The essential advantage of the synthesizer approach is that the differentially private dataset can be analyzed any number of times without increasing the privacy risk. Therefore, it enables collaboration between several parties, democratizing knowledge, or open dataset initiatives.
While the synthetic dataset embodies the original data’s essential properties, it is mathematically impossible to preserve the full data value and guaranteeing record-level privacy at the same time. Usually, we can’t perform arbitrary statistical analysis and machine learning tasks on the synthesized dataset to the same extent as it is possible with the original data. Therefore, the type of downstream job should be considered before the data is synthesized.
For instance, the workflow for generating a synthetic dataset for supervised machine learning with SmartNoise looks as follows:
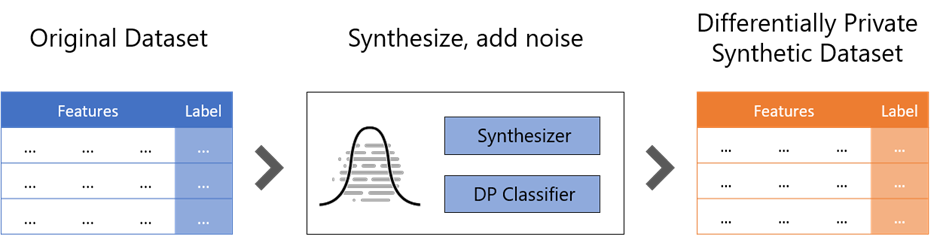
Various techniques exist to generate differentially private synthetic data, including approaches based on deep neural networks, auto-encoders, and generative adversarial models.
The new release of SmartNoise includes the following data synthesizers:
| Supported Synthesizer | Overview |
|---|---|
| Multiplicative Weights Exponential Mechanism (MWEM) |
|
| Differentially Private Generative Adversarial Network (DPGAN) |
|
| Private Aggregation of Teacher Ensembles Generative Adversarial Network (PATEGAN) |
|
| DP-CTGAN |
|
| PATE-CTGAN |
|
| Qualified Architecture to Improve Learning (QUAIL) |
|
Check out our research paper to learn more about synthesizers and their performance in machine learning scenarios.
Data protection in companies, government authorities, research institutions, and other organizations is a joint effort that involves various roles, including analysts, data scientists, data privacy officers, decision-makers, regulators, and lawyers.
To make the highly effective but not always intuitive concept of differential privacy accessible to a broad audience, we have released a comprehensive whitepaper about the technique and its practical applications. In the paper, you can learn about the underestimated risks of common data anonymization practices, the idea behind differential privacy, and how to use SmartNoise in practice. Furthermore, we assess different levels of privacy protection and their impact on statistical results.
The following example compares the distribution of 50,000 income data points to differentially private histograms of the same data, each generated at different privacy budgets (controlled by the parameter epsilon).
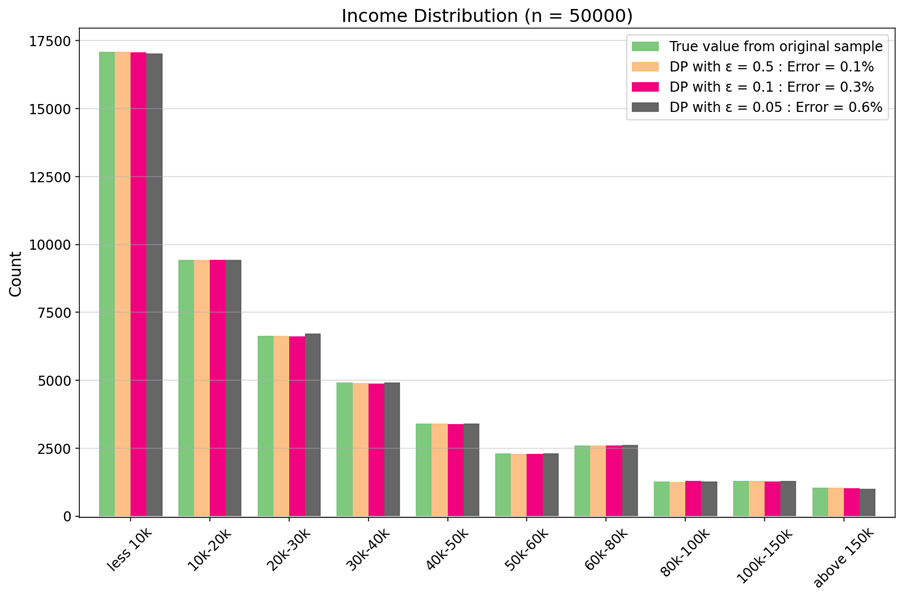
Lower epsilon values lead to a higher degree of protection and are therefore also associated with a more intense statistical noise. Even in the aggressive privacy setting with an epsilon value of 0.05, the differentially private distribution reflects the original histogram quite well. It turns out, that the error can be reduced further by increasing the amount of data.
Accompanying the whitepaper, several Jupyter notebooks are available for you to experience SmartNoise and other differential privacy technologies in practice and adapt them to your use cases. The demo scenarios range from protecting personal data against privacy attacks, providing basic statistics to advanced machine learning and deep learning applications.
Protecting Statistics Against Reconstruction Attacks
Learn how attackers might reconstruct sensitive income information based on released summary statistics. SmartNoise can help you protect

Protecting Sensitive Data Against Re-Identification Attacks
Learn how attackers might combine an anonymized medical dataset with other available data to identify patients. See how to use SmartNoise to protect personal data against re-identification attacks.

Privacy-Preserving Statistical Analysis
Learn how to use SmartNoise to disclose statistical reports with the differential privacy concept.
Understand how different levels of privacy guarantees and data set sizes impact statistical accuracy.

Machine Learning Using a Differentially Private Classifier
Check out different options to perform differentially private machine learning for a classification task. Experience how different levels of privacy guarantees, and data set sizes affect model quality.

Generating a Synthetic Dataset for Privacy-Preserving Machine Learning
See how SmartNoise can be used to generate a differentially private dataset that can be disclosed without privacy concerns. Check out how the synthetic dataset can be used for machine learning.

Detect Pneumonia in X-Ray Images while Protecting Patients’ Privacy
Discover how to perform differentially private deep learning by analyzing medical images.
To make the differential privacy concept generally understandable, we refrain from discussing the underlying mathematical concepts. Rather, we seek to keep the technical descriptions at a high level. Nonetheless, we recommend that readers have background knowledge about and understand machine learning concepts.
We have introduced the SmartNoise Early Adopter Acceleration Program to support the usage and adoption of SmartNoise and OpenDP. This collaborative program with the SmartNoise team aims to accelerate the adoption of differential privacy in solutions today that will open data and offer insights to benefit society.
If you have a project that would benefit from using differential privacy, we invite you to apply.
In partnership with IBM, we’re releasing the source code to MS-DOS 4.00 under the MIT license to support open innovation.

Our focus this past year has been on security, business excellence in OSS, safety, and supporting our upstream.

Join Microsoft at Open Source Summit North America 2024, taking place in Seattle, Washington from April 16 to 18, 2024.

Microsoft is excited to be able to support and contribute to the cloud-native and open-source communities at KubeCon Europe 2024.