

Introducing the Agent Governance Toolkit: Open-source runtime security for AI agents
Microsoft unveils the Agent Governance Toolkit to bring OS‑level security, trust, and compliance to autonomous AI agents.

Organizations that want to leverage AI at scale must overcome a number of challenges around model training and model inferencing. Today, there are a plethora of tools and frameworks that accelerate model training but inferencing remains a tough nut due to the variety of environments that models need to run in. For example, the same AI model might need be inferenced on cloud GPUs as well as desktop CPUs and even edge devices. Optimizing a single model for so many different environments takes time, let alone hundreds or thousands of models.
In this blog post, we’ll show you how Microsoft tackled this challenge internally and how you can leverage the latest version of the same technology.
At Microsoft we tackled our inferencing challenge by creating ONNX Runtime. Based on the ONNX model format we co-developed with Facebook, ONNX Runtime is a single inference engine that’s highly performant for multiple platforms and hardware. Using it is simple:
Today, ONNX Runtime is used in millions of Windows devices and powers core models across Office, Bing, and Azure where an average of 2x performance gains have been seen. Here are a few examples:
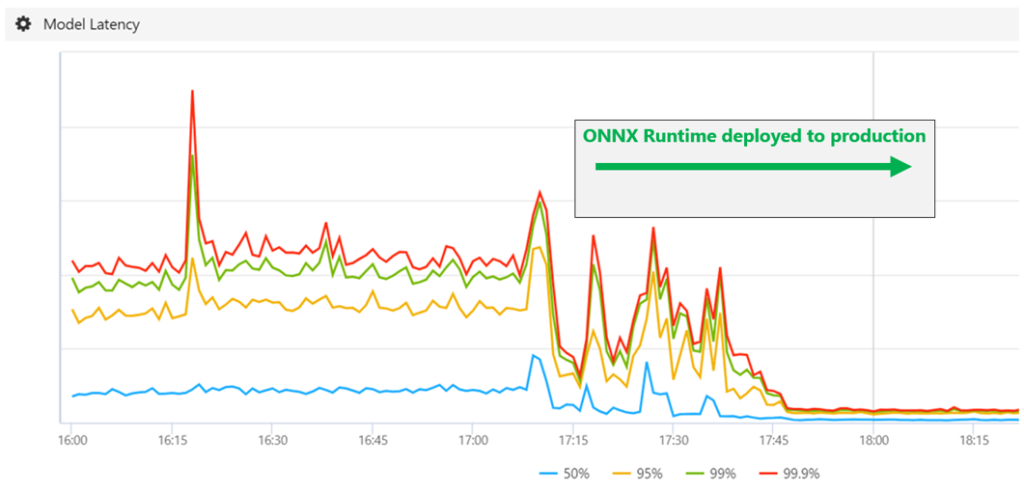
Having seen significant gains internally, we open sourced ONNX Runtime in December 2018. We also began working with leading hardware partners to integrate their technology into ONNX Runtime to achieve even greater performance.
6 months after open sourcing, we are excited to release ONNX Runtime 0.4, which includes the general availability of the NVIDIA TensorRT execution provider and public preview of Intel nGraph execution provider. With this release, ONNX models can be executed on GPUs and CPUs while leveraging the respective neural network acceleration capabilities on these platforms. Developers can write their application once using the ONNX Runtime APIs and choose the specific ONNX Runtime base container image to build their deployment image for the targeted hardware. Microsoft will publish pre-built Docker base images for developers to integrate with their ONNX model and application code and deploy in Azure Kubernetes Service (AKS). This gives developers the freedom to choose amongst different hardware platforms for their inferencing environment.
In addition, ONNX Runtime 0.4 is fully compatible with ONNX 1.5 and backwards compatible with previous versions, making it the most complete inference engine available for ONNX models. With newly added operators in ONNX 1.5, ONNX Runtime can now run important object detection models such as YOLO v3 and SSD (available in the ONNX Model Zoo).
To enable easy use of ONNX Runtime with these execution providers, we are releasing Jupyter Notebooks tutorials to help developers get started. This notebook uses the FER+ emotion detection model from the ONNX Model Zoo to build a container image using the ONNX Runtime base image for TensorRT. Then this image is deployed in AKS using Azure Machine Learning service to execute the inferencing within a container.
The release of ONNX Runtime 0.4 with execution providers for Intel and NVIDIA accelerators marks another milestone in our venture to create an open ecosystem for AI. We will continue to work with hardware partners to integrate their latest technology into ONNX Runtime to make it the most complete inference engine. Specifically, we are working on optimizations to target mobile and IOT edge devices, as well as supporting new hardware categories such as FPGAs. For instance, we are releasing a private preview of the Intel OpenVINO execution provider, allowing ONNX models to be executed across Intel CPUs, integrated GPUs, FPGAs and VPUs for edge scenarios. Public preview of this execution provider will be coming soon. Ultimately, our goal is to make it easier for developers using any framework to achieve high performance inferencing on any hardware.
Have feedback or questions about ONNX Runtime? File an issue on GitHub and follow us on Twitter.
Microsoft unveils the Agent Governance Toolkit to bring OS‑level security, trust, and compliance to autonomous AI agents.

From improving reliability and performance to advancing security and AI-native workloads, our goal remains the same: make Kubernetes better for everyone.

DocumentDB Kubernetes Operator enables you to deploy and manage open-source DocumentDB on Kubernetes. Simplify cloud-native database operations today.

Drasi turns one with GQL support—giving developers more ways to build change-driven systems.