In the Part I of this blog post, we discussed why many customers are choosing the MEAN (Mongo, Express, Angular, and Node) stack as an efficient and powerful approach to building web applications. We also reviewed how to get started with Express, Angular and Node development on Azure.
Today, in Part II, we’ll turn our attention to the “M” in MEAN. Specifically, we’ll discuss some additional points to consider when standing up a highly available, fault-tolerant MongoDB cluster on Azure.
Enterprise-grade MongoDB clusters on Azure – the IaaS approach
There are massive MongoDB instances running on Microsoft Azure Virtual Machines. I’ve enjoyed helping some of these customers with their initial architectures and performance requirements. Some of these enterprises take advantage of sharding, some don’t. However, all production instances use replication. These instances perform well on Azure because the architectural plans considered best practices for public cloud, and specifically, Microsoft Azure.
Keeping that in mind, I will walk you through a reference architecture for a 3-way sharded instance of MongoDB on Microsoft Azure, where each shard is also 3-way replicated. This architecture is optimized for Azure, and can act as a base template for a production or staging cluster using MongoDB 3.2 or higher.
Reference Architecture – 3-way sharded, 3-way replicated MongoDB on Azure
There are a few things that a MongoDB architect should keep in mind when it comes to Microsoft Azure – or for that matter, any cloud.
Here is a checklist for thinking through requirements for a distributed MongoDB architecture:
What kind of VMs should I use? How much RAM? How much CPU horsepower?
What kind of disk storage is needed? Ephemeral or persistent? Standard or premium?
Should each shard group have its own subnet? Or should they all be clubbed into one subnet?
What about security and access? Which users should be able to log into the machines? Do we need a jump box?
If we are using MongoDB 3.2 (or above) and sharding, do we deploy the configuration servers as a replica set or not?
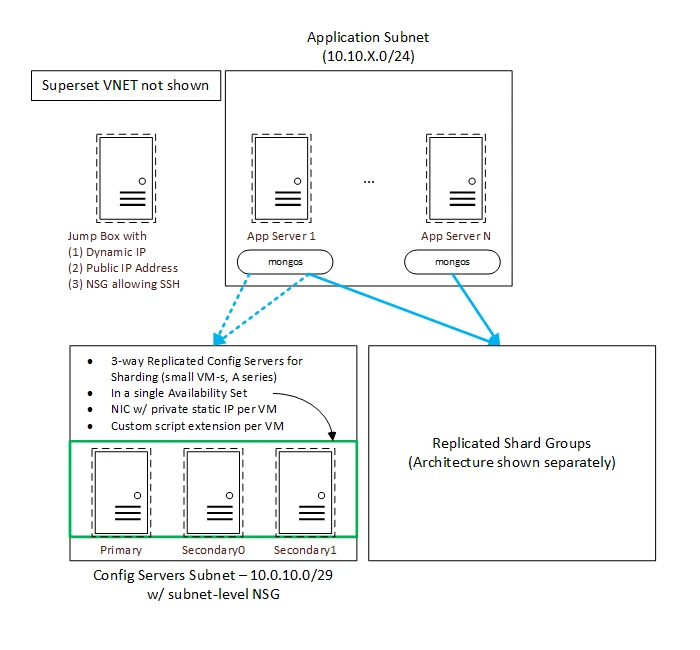
Below is a reference architecture for a 3-way sharded MongoDB 3.2 cluster on Microsoft Azure, where each shard is also 3-way replicated. It is broken down into two pieces – Figure 1 one shows the app servers (clients) in their own subnet, the replica set of three configuration servers and the jump box. Config servers are needed by MongoDB if you are using sharding. They store the sharding metadata, and tell mongos (the client) which shard group to contact for a specific piece of data.
Figure 1
Subnet allocation: It is not necessary for the app servers, the configuration servers, or the individual shard groups to be in their own subnets. You can put the entire footprint in one subnet. The determining factor here, usually, is the flow/isolation of traffic and usage of the NSG (Network Security Group) at the subnet level. If you have different sets of servers with different requirements, as far as which ports need to be opened for incoming or outgoing traffic, it is more convenient to put them in separate subnets and associate different NSGs to them.
Remember that in Azure, NSGs can also be associated at the Network Interface (NIC) level, so even if you lump everything up in a single subnet, it is theoretically possible to control traffic at a more granular VM level and still get security right. It is just more work, as it is more virtual appliances to keep track of.
Also, remember that Azure lets you associate NSGs at both subnet and NIC levels. Azure has simple-to-understand overriding policies, where rules for one NSG will override the other. Azure provides a ton of knobs and levers to tweak things and get your desired outcome.
Config servers: In this architecture, the configuration servers are 3-way replicated. MongoDB has added this feature beginning version 3.2. The mongos instances read the sharding configuration from these configuration servers. This architecture assumes that it is okay to run mongos on the app servers. There may be cases where it is not.
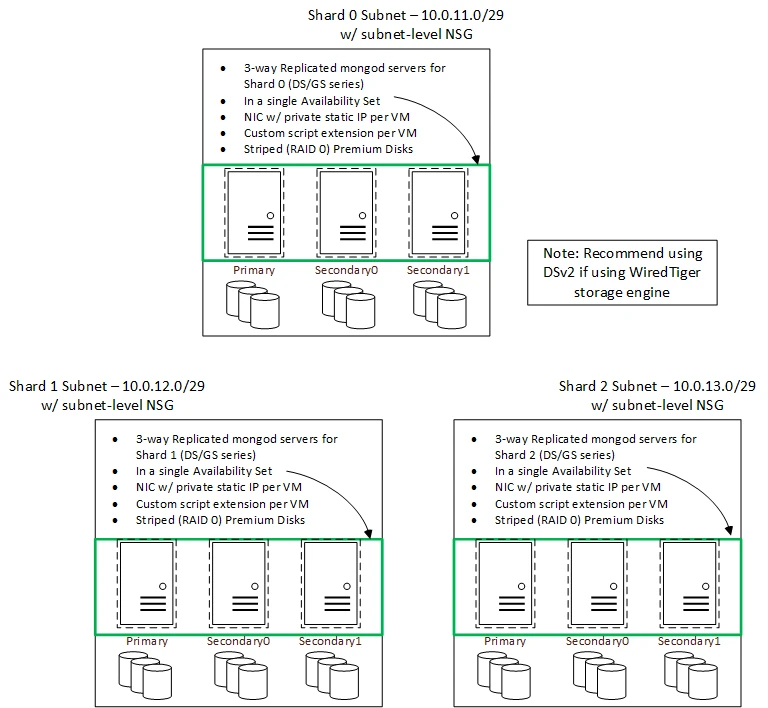
Figure 2 is the rest of the architecture showing the actual database servers (3 shard groups, each replicated 3-way, meaning it shows 9 VMs, each shard group in its own subnet). This goes into the empty box in Figure 1.
Figure 2
Architecture notes:
Superset Microsoft Azure Virtual Network (VNET) is not shown.
For Shard 0 through Shard 2, each shard group is 3-way replicated.
Recommend using Premium Storage (which uses SSD Disks) for higher IOPS.
Striping: Recommend adding additional data disks and striping them using RAID 0 with mdadm; as striping gives better disk i/o performance. With Microsoft Azure, one does not really need to consider other RAID levels, as redundancy is built into Azure storage (by way of LRS, GRS, ZRS and read-only-GRS options).
CIDR Notations used: The IP addresses shown here are just for reference. 10.0.X.0/29 only allows four usable private IP addresses in a subnet. Using that sends a message to future architects, who may need to expand this footprint, to help them understand the original intentions.
Choice of Azure VM SKU: WiredTiger storage engines has built-in compression, which will likely take up slightly more CPU. Hence the recommendation is DSv2 VMs because the V2 series VMs run 35% faster than regular D-series VMs. A lot of time, these choices are affected by pricing and budget, as well as by region of deployment. Thorough testing is needed for any given set of applications.
Azure availability sets: Microsoft Azure availability sets (green rectangles above) ensure that at least one of the three VMs is always running. If one or even two goes down for some time, MongoDB replication will make sure that they catch up when come back up.
Why are load balancers not shown?
Azure internal load balancers (ILBs) are great tools for distributing incoming traffic across multiple VMs. However, the distribution modes supported by Azure ILBs are not of much use here.
Let me explain. Consider any availability set in Figure 2 above – it has three VMs. If you put a load balancer on top of that set, it will distribute traffic to go to all three. However, you do not want that with a MongoDB replica set. The request should always land on the primary host of the replica set. If that host goes down, MongoDB is smart enough to start using the secondary hosts. During this automatic failover process, MongoDB 3.2 initiates automatic rollback (if needed) to protect the integrity of data, and one of the secondary hosts elects itself to be the leader. We should use the replication protocol version 1 (as opposed to version 0) for accelerated failover.
Thus, in this particular case, the problem of failover is solved by the software being installed on Azure – hence, Azure does not need to solve for it explicitly. Azure provides the guarantee that all three will not go down at once, which is ensured by the availability sets.
Automation and Continuous Integration
Azure CLI (Command Line Interface) or Powershell (which is open sourced and Mac/Linux friendly) can automate the above deployment, invoking JSON ARM templates, which lets us tear it down and stand it up as many times as we like in a repeatable, predictable way. Here, we start reaping the benefits of the cloud. Azure provides many options as far as automation is concerned.
The architecture discussed in Figure 1 and Figure 2 refers to the “Custom Script Extension.” This is a very cool Azure feature that lets us automate the installation of software after the VMs, subnets, NSGs and other infrastructure pieces have been deployed by automated means.
For example, in order to build out the above architecture manually and have it work, one has to:
a. First, build the infrastructure (all VMs, subnets, NSGs, NICs, IP Addresses, etc.) b. Second, run the right scripts to install correct software on each VM. The actual database server will install different bits than the configuration server. Each server will need some tweaks to configuration files so that they start talking to each other. This entire process is documented here.
In “a” immediately above, the infrastructure can be automated using JSON ARM templates, which can then be invoked using Azure CLI, PowerShell or Azure automation. We also have a choice of using 3rd party tools like Terraform and Packer. Packer makes custom image management a breeze, in case these VMs are being spun up from a custom Linux image. Using a custom image is not required, one can always start from the standard gallery image in Azure and make changes to it using the same mechanism described in Figure 2 above. However, in most real cases, custom images are used to ensure security and compliance, and Azure has great ways to manage and automate that as well.
In “b” immediately above, the scripts can be automated using “Custom Script Extensions.” The automation loop for Figure 2 can be invoked from within the automation script of Figure 1, so the entire thing can be built and torn down automagically over and over again – which is useful for custom CI/CD pipelines and running tests.
MEAN on Azure: revolutionizing modern web development
In summary, MEAN and Azure together are a great combination for modern web applications. The MEAN stack has revolutionized rapid website development, and taken a big leap forward by introducing big data to web applications via a NoSQL database as well as modernized development by standardizing on JSON. Combining MEAN with Azure’s IaaS approach can be incredibly powerful, given Microsoft’s support for hybrid scenarios, where customers have the choice and flexibility to move certain workloads to the cloud, while keeping others in their datacenters.
Give the MEAN on Azure a try today with a free trial!
Questions or other topics you’d like to see on the blog? Let me know in the comments!
Koushik Biswas
Director, Technology Strategy, Microsoft Open Source Specialist Sales
Koushik Biswas is passionate about anything open source, led Yahoo’s global CDN, edge delivery and distributed caching teams before joining Microsoft's OSS revolution.
Open source is the foundation for AI and, as AI workloads scale, developers need that foundation to be more secure, more predictable, and easier to build apps and agents.