



A Kubernetes cluster requires compute resources to run applications and these resources may need to increase or decrease depending on the application requirements. This typically falls under the category of “scaling” and can be broadly divided into cluster and application scaling.
To deal with increasing requirements, such as high traffic, you can scale out your application by running multiple instances. In Kubernetes, this is equivalent to scaling a deployment to add more pods.
You can do it manually, but the Horizontal Pod Autoscaler is a built-in component that can handle this automatically. You might also need to scale out the underlying Kubernetes nodes, such as virtual machines, bare metal instances, etc. This can also be done manually, but you can use a cluster autoscaler that will scale your cluster up and down in an automated fashion.
This blog series will cover open source components that can be used on top of existing Kubernetes primitives to help scale Kubernetes clusters, as well as applications. We will explore:
- Virtual Kubelet, an open source Kubernetes kubelet implementation that allows Kubernetes nodes to be backed by providers, including serverless cloud container platforms.
- Kubernetes Event-driven Autoscaling (KEDA), which is another open source component that can be added into any Kubernetes cluster to drive the scaling of any container based on the workload.
Here is a breakdown of the blog posts in this series:
- Part 1 (this post) will cover basic KEDA concepts
- Part 2 will showcase KEDA auto-scaling in action with a practical example
- Part 3 will introduce Virtual Kubelet
- Part 4 will conclude the series with another example to demonstrate how KEDA and Virtual Kubelet can be combined to deliver scalability
In this post, you will get an overview of KEDA, its architecture, and how it works behind the scenes. This will serve as a good foundation for you to dive into the next post, where you will explore KEDA hands-on with a practical example.
Overview
KEDA (Kubernetes-based Event-driven Autoscaling) is an open source component developed by Microsoft and Red Hat to allow any Kubernetes workload to benefit from the event-driven architecture model. It is an official CNCF project and currently a part of the CNCF Sandbox. KEDA works by horizontally scaling a Kubernetes Deployment or a Job. It is built on top of the Kubernetes Horizontal Pod Autoscaler and allows the user to leverage External Metrics in Kubernetes to define autoscaling criteria based on information from any event source, such as a Kafka topic lag, length of an Azure Queue, or metrics obtained from a Prometheus query.
You can choose from a list of pre-defined triggers (also known as Scalers), which act as a source of events and metrics for autoscaling a Deployment (or a Job). These can be thought of as adapters that contain the necessary logic to connect to the external source (e.g., Kafka, Redis, Azure Queue) and fetch the required metrics to drive autoscaling operations. KEDA uses the Kubernetes Operator model, which defines Custom Resource Definitions, such as ScaledObject, which you can use to configure autoscaling properties.
Pluggability is built into KEDA and it can be extended to support new triggers/scalers
High-level architecture
At a high level, KEDA does two things to drive the autoscaling process:
- Provides a component to activate and deactivate a Deployment to scale to and from zero when there are no events
- Provides a Kubernetes Metrics Server to expose event data (e.g., queue length, topic lag)
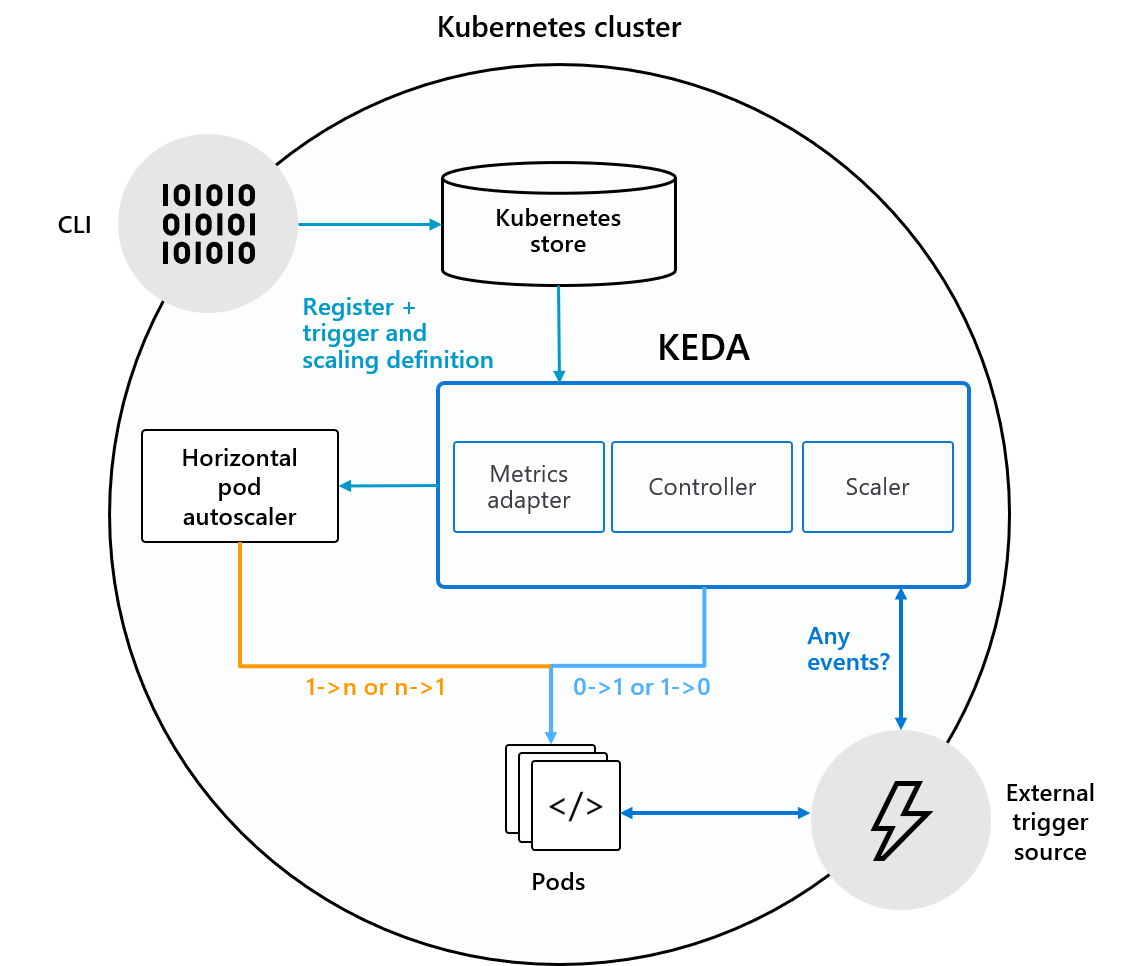
KEDA uses three components to fulfill its tasks:
Scaler: Connects to an external component (e.g., Kafka) and fetches metrics (e.g., topic lag)Operator(Agent): Responsible for “activating” a Deployment and creating a Horizontal Pod Autoscaler objectMetrics Adapter: Presents metrics from external sources to the Horizontal Pod Autoscaler
Let’s dive deeper into how these components work together.
Scaler
As explained earlier, a Scaler is defined by a ScaledObject (Custom Resource) manifest. It integrates with an external source or triggers defined in the ScaledObject to fetch the required metrics and present them to the KEDA metrics server. KEDA integrates multiple sources and also makes it possible to add other scalers or external metric sources using a pluggable interface.
Some of the scalers include:
- Apache Kafka: based on Kafka topic lag
- Redis: based on the length of a Redis list
- Azure Service Bus: based on Azure Service Bus queues or topics
- Google Cloud Platform Pub/Sub: based on a number of messages in a GCP Pub/Sub subscription
- Prometheus: based on the result of a PromQL query
A current list of scalers is available on the KEDA home page.
The KEDA Operator consists of a controller that implements a “reconciliation loop” and acts as an agent to activate and deactivate a deployment to scale to and from zero. This is driven by the KEDA-operator container that runs when you install KEDA.
It “reacts” to the creation of a ScaledObject resource by creating a Horizontal Pod Autoscaler (HPA). It’s important to note that KEDA is responsible for scaling the deployment from zero to one instance and scaling it back to zero while the HPA takes care of auto-scaling the Deployment from there.
However, the Horizontal Pod Autoscaler also needs metrics to make the autoscaling work. Where does it get the metrics from? Enter the Metrics Adapter!
Metrics Adapter
In addition to defining a Custom Resource Definition and a controller/operator to act upon it, KEDA also implements and acts as a server for external metrics. To be precise, it implements the Kubernetes External Metrics API and acts as an “adapter” to translate metrics from external sources (mentioned above) to a form that the Horizontal Pod Autoscaler can understand and consume to drive the autoscaling process.
How can you use KEDA?
Although we will go through the details in the subsequent blog post, here is a quick peek at how one might use KEDA from a developer’s perspective. Once it is installed to your Kubernetes cluster, this is how you would typically use KEDA (for details, please refer to the examples available at https://github.com/kedacore/samples).
- Create a
Deployment(or aJob): This is simply the application you want KEDA to scale based on a scale trigger. Apart from that, it is completely independent. - Create a
ScaledObject: This is the custom resource definition, with which you can define the source of metrics, as well as autoscaling criteria.
Once this is done, KEDA will start collecting information from the event source and drive the autoscaling accordingly. Here is an example of a ScaledObject, which defines how to autoscale a Redis list consumer called processor that is running in a cluster as a Kubernetes Deployment.
apiVersion: keda.k8s.io/v1alpha1
kind: ScaledObject
metadata:
name: redis-scaledobject
namespace: default
labels:
deploymentName: processor
spec:
scaleTargetRef:
deploymentName: processor
pollingInterval: 20
cooldownPeriod: 200
minReplicaCount: 0
maxReplicaCount: 50
triggers:
- type: redis
metadata:
address: redis:6739
listName: jobs
listLength: "20"
authenticationRef:
name: redis-auth-secret
Notice that the ScaledObject definition is largely divided into two parts: one that is generic and the other one that is specific to the event source (Redis has been used as an example).
The generic parameters consist of:
scaleTargetRef.deploymentName: the name of theDeploymentyou want to autoscaleminReplicaCount: minimum number of replicas that KEDA will scale the deployment down to. You can scale down to zero, but it’s possible to use any other valuecooldownPeriod: the period to wait after the last trigger reported active before scaling the deployment back tominReplicaCountpollingInterval: the interval to check each trigger onmaxReplicaCount: the maximum number of replicas that KEDA will scale the deployment out to
The event source or trigger specific parameters are:
triggers.type: the event source being used (e.g.,redis)triggers.metadata: attributes that differ from trigger to trigger (e.g., in case ofredis, its address,listName, andlistLength)triggers.authenticationRef: allows you to refer to aTriggerAuthenticationobject, which is another KEDA-specific object to capture the authentication mechanism of an event source
Conclusion
KEDA is a lightweight component that can be added into any Kubernetes cluster to extend its functionality. It can be used to autoscale a variety of workloads ranging from traditional deployments to FaaS (serverless functions).
You can explicitly choose and configure specific applications (Deployment and Job) that you want KEDA to autoscale without impacting other components. KEDA will ensure that your application is scaled down to zero instances (configurable), unless there is work to do. And last but not the least, it is extensible. You can integrate custom event sources in the form of scalers to drive the autoscaling process.
Stay tuned for the next installment in this series, where we will dive deeper into KEDA with the help of a practical example. Other questions or comments? Please let me know in the comments below.








