



In summer 2019, I worked as a high school intern for the ONNX AI team at Microsoft and loved working on various projects with the team, including the BERT text classification model. However, due to Covid-19, the Microsoft Internship Program for high school students was canceled in the summer of 2020. This led two other former interns and I to reach back out to the AI team, landing positions as open source developers for the summer.
Today, I’d like to share our work on two meaningful projects, RoBERTa text-classification and DeepVoice3 text-to-speech models. I spent the summer converting these models into the ONNX format and contributing them to the ONNX model zoo, a collection of pre-trained, state-of-the-art ONNX models from community members.
RoBERTa
RoBERTa is a Natural Language Processing (NLP) model and an optimized version of BERT (Bidirectional Encoder Representations from Transformers). This transformer model is a complex model with multiple HEADs and functionalities. For my project, I specifically worked with the RoBERTa-base model with no HEAD and RoBERTa sentiment analysis model, training the base model with the model weights provided by HuggingFace. Due to RoBERTa’s complex architecture, training and deploying the model can be challenging, so I accelerated the model pipeline using ONNX Runtime.
As you can see in the following chart, ONNX Runtime accelerates inference time across a range of models and configurations.
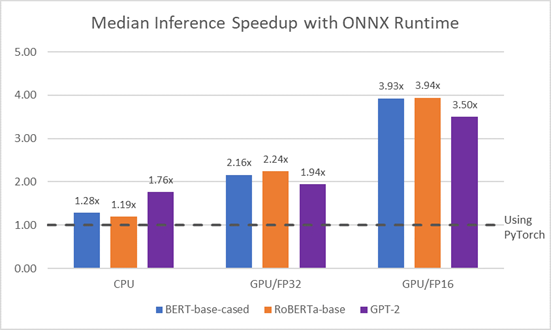
For the sentiment analysis model, I trained it with the model weights from the alibi datasets that use the Cornell movie-review dataset. As this model used a different dataset apart from the one provided by HuggingFace, I faced a lot of issues with training the model. Training was completed over the course of two days, 1239 epochs. Since I didn’t have access to a GPU, I trained using a CPU. I also generated the MCC (Matthews Correlation Coefficient) validation score for the model.

I also had trouble with the post-processing code for this model. After researching and understanding the output produced by the model, I was able to figure out the code. I converted both models into ONNX format. In order to add these models to the zoo, I created a pull request, containing the model files, the Jupyter notebooks for inference and validation of the sentiment analysis model, and pre-processing and post-processing code to help the user run the model. Here is the link to the RoBERTa model in the zoo.
DeepVoice3
DeepVoice3 is a text-to-speech (TTS) model, where the input is a sentence and the output is the audio of that sentence. Currently, the ONNX model zoo does not have any speech and audio processing models, so I started work on DeepVoice3 and aimed to contribute an audio model to the zoo.
However, I faced several issues converting this TTS model to ONNX. The main challenge was the input that the ONNX exporter allowed. The exporter only allowed a three-parameter input that was generated over an array of sentences. But the original PyTorch model required an input of two parameters of features generated over each individual sentence.
To test it, I converted the model using the three parameters input. Due to the input difference, the converted ONNX model did not produce the right audio output. I studied the DeepVoice3 model architecture to understand how the encoder and decoder methods work and went through the test files provided by the DeepVoice3 GitHub.
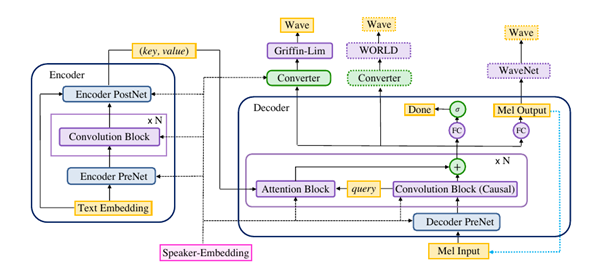
During my research of other TTS models that were successfully converted to ONNX, I discovered that in the past there were some issues regarding converting TTS models to ONNX, specifically because of the decoder method that TTS models use. I questioned if DeepVoice3 was compatible with ONNX and filed an issue in the PyTorch repository regarding the conversion error. I have been talking to some engineers to come up with a solution.
However, I still wasn’t sure if the problem was that the model was not compatible with ONNX or that there was an issue within the Pytorch model itself. I talked to some engineers within the ONNX team. After discussing, we agreed that there were several issues within the model, especially how the Decoder method was built that made it difficult to export the right ONNX model.
Adding a text-to-speech model to the ONNX model zoo will be the subject of ongoing exploration.
Takeaways
Being able to add the RoBERTa model to the ONNX model zoo gives users of the zoo more opportunities to use natural language processing (NLP) in their AI applications, with the extra predictive power that RoBERTa provides. Personally, I gained a better understanding of the NLP domain and transferred this knowledge into the materials in the zoo, by way of the notebooks, as well as pre and post processing code. As a new open source developer, I learned a lot about git, pull requests, and the GitHub community review process, which will stand me in good stead for future open source contributions.
I am grateful to my mentors Vinitra Swamy and Natalie Kershaw who have dedicated their time for weekly meetings and guided me throughout the project.
Questions or feedback about these projects? Let us know in the comments below.








