



An open-source benchmark that measures what memory does for AI agents in production
Everyone agrees that agents need memory in production. What we still don’t have is a good way to tell how much memory helps. Most memory benchmarks are just retrieval tests: fetch a name from 50 turns ago or surface a fact from a long chat. That tells you the pipe works. It doesn’t tell you that the agent performs better.
This gap matters in enterprise workflows. Customer support agents don’t break because the agent forgot a fact; they break because it botched the procedure. It skips policy checks, surfaces incomplete user details, uses domain tools incorrectly or inefficiently, and repeats the same failure mode.
That’s why we built STATE-Bench (Stateful Task Agent Evaluation Benchmark): an open-source, memory-agnostic benchmark that measures whether agents improve with experience on realistic enterprise tasks. Today we are making it freely available to agent developers, researchers, and platform teams.
This release covers three domains: customer support, travel, and shopping, with 450 tasks spanning policy compliance, information synthesis, and multi-step reasoning procedures. Watch the Open at Microsoft episode to hear more about the motivation and people behind this work.
We focus on enterprise scenarios because they stress the exact failure modes we see in production. These tasks share three properties:
- Procedural: The agent must follow a domain-specific procedure to execute tasks like looking up a booking, validating user eligibility, checking policy, calculating fees, confirming, then executing. Skip a step and the outcome is usually wrong.
- Stateful: Enterprise agents go beyond conversational chats; they change system state in a database (refund records, booking status, account updates). Mistakes aren’t bad answers; they create real cost and cleanup.
- User experience: In addition to task success, the benchmark assesses the quality of the user’s interaction with the agent. We developed a detailed rubric with strict guidance on what a user-centric experience should look like (see the metrics section below).
The evaluation loop
In STATE-Bench, each task is a self-contained scenario with a pre-populated database of artifacts (e.g. bookings, orders, carts), a customer with a specific problem, and a set of deterministic state assertions that define success.
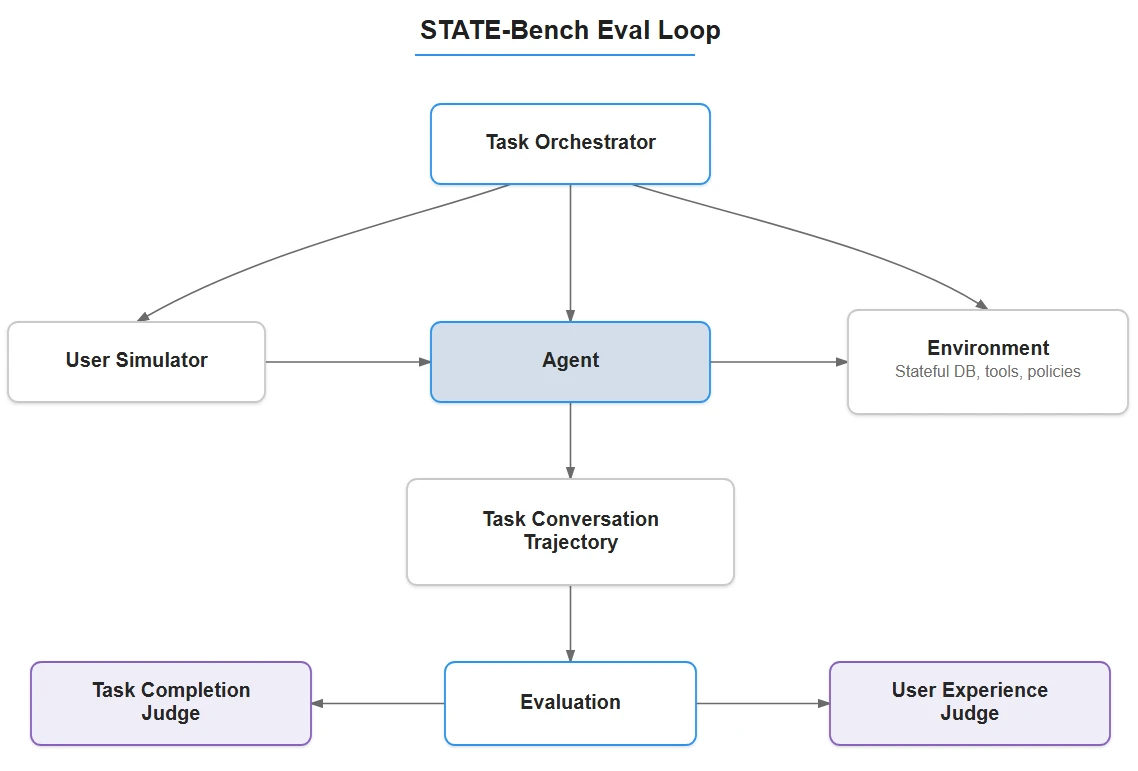
The orchestrator runs a multi-turn conversation loop. On each turn, the agent receives the full conversation history and responds with tool calls and texts. Tools execute against a stateful environment: e.g. looking up a booking, checking a policy, and then the user simulator responds naturally, revealing information only when asked. The loop continues until the task is resolved, or the turn limit is reached.
The LLM-based user simulator is central to STATE-Bench. It keeps user details consistent, pushes back when appropriate, and forces the agent to gather missing information instead of making assumptions. Each simulator also has a lightweight personality—for example, one user may be impatient and provide incomplete details, while another gives everything upfront.
To keep evaluation stable, the simulator follows an exhaustive, task-specific rule set and does not respond outside of it. In testing, simulator-induced variance was about 1%, mostly from raw LLM noise—so success or failure reflects on the agent, not the simulator.
Rigorous metrics for production readiness
STATE-Bench evaluates agents across four dimensions: whether they complete tasks, whether they do so consistently across runs, how efficiently they operate, and how well they communicate with users.
- Task completion rate: Running each task five times and reporting the average completion rate. For state-mutating tasks, a deterministic scorer compares the final environment state to ground truth. For procedural and informational tasks, an LLM judge evaluates whether the agent followed the expected process.
- Agent reliability: Reporting pass^5, the percentage of tasks that succeed on all five runs, capturing execution consistency.
- Agent efficiency: Measuring the average cost to complete a task, including turns, unnecessary tool calls, and all input, output, and retrieval tokens.
- User experience score: An LLM judge scores the full conversation on user experience using a one to five rubric along five dimensions. For example, user ease captures how much effort the user had to expend, while user consent measures whether the agent sought confirmation and presented options before acting.
Together, these metrics provide a multi-dimensional view of agent performance, capturing task outcomes, consistency across runs, operational cost, and interaction quality. In this benchmark, memory systems can then be compared on whether they are associated with changes in reliability, progress on harder tasks, turn count, and user experience.
Quantifying the memory gap
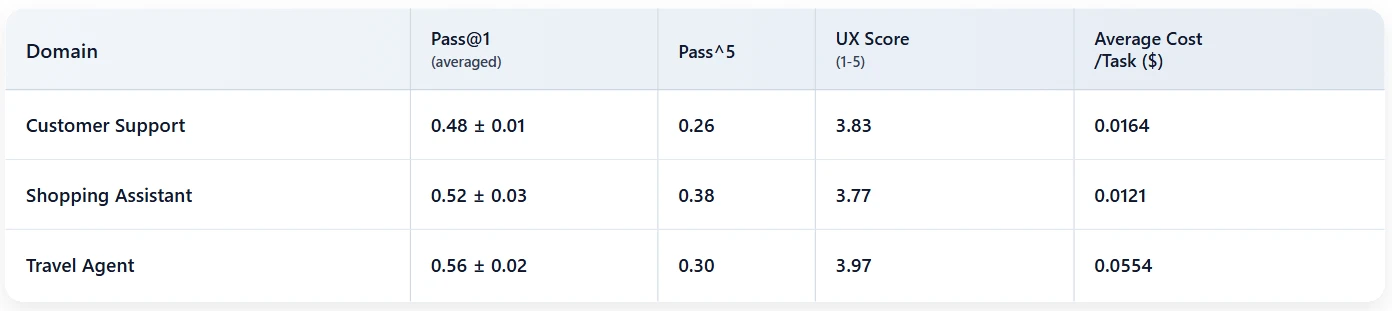
We established a baseline on STATE-Bench using GPT-5.1 without memory, running each task five times across three domains. Despite strong prompting and full tool access, the model completes fewer than half of the tasks reliably. The pass^5 results are particularly instructive: in travel, only about 30% of tasks succeed across all five runs.
The gap between average pass@1 and pass^5 underscores the central challenge: agents can be inconsistent even when given identical tasks. We believe this is precisely the failure mode memory is intended to mitigate.
Bring your own memory—an open challenge
STATE-Bench provides tasks, environment, tools, user simulator, and scoring. It offers a reproducible, open standard to answer the questions that matter in production: Does my memory system make my agent more reliable? Does it reduce the turns needed to complete a task? Does it improve user experience? Rather than relying on internal benchmarks or anecdotal testing, you now have a shared framework the community can build on and compare against.
STATE-Bench is built for three audiences:
- Agent developers: Measure whether adding memory improves your agent’s reliability, task completion, and efficiency.
- Researchers: A reproducible, open benchmark for comparing memory architectures and approaches.
- Platform builders: A framework for evaluating memory as a component of a larger agent stack, with a pluggable interface to test your own implementation.
STATE-Bench is fully open source:
- 450 tasks across three domains (travel, customer support, shopping), with pre-populated environments, user simulators, and deterministic assertions.
- Domain-agnostic evaluation framework (orchestrator, scoring, and metrics).
- Pluggable agent interface. (Bring your own memory.)
- Task generation and auditing tools to validate task correctness and solvability.
And it is available at GitHub: STATE-Bench. Star the repo, run the benchmark, and share what you build. Run the no-memory baseline to establish your starting point; plug in your memory system using the bring your own memory interface; compare results across all four metrics; and share your findings with the community.
STATE-Bench
Learn how you can use the open-source benchmark to measure agent improvement.









