



Microservices built on Kubernetes are fast becoming one of the core scenarios where computing is done, and Kubernetes development and operations skills are therefore becoming a larger part of any cloud-native toolset. This article shows how to use Brigade, along with other tools from the Cloud Native Computing Foundation (CNCF), to build a Kubernetes-native application that listens for events and then runs serverless pipelines on Virtual Kubelet instances, each of which are dynamically created (and recycled when the pipeline is done).
The CNCF sandbox projects used in this article are:
- Cloud Events, a specification for describing event data in a common way
- Brigade, a Kubernetes-native service that creates structured container pipelines
- Virtual Kubelet, an open-source Kubernetes kubelet implementation that defers its internal execution to another system.
Both Brigade and an implementation of Virtual Kubelet based on Azure Container Instances (ACI) are installed using the CNCF Helm project, an installer for Kubernetes applications.
In addition, we were happy to announce last week that Brigade is now a CNCF sandbox project, a major step for the Brigade community, collaborating on a first-class scripting runtime for constructing container pipelines.
Why these projects? The nature of event-driven applications is that the load is often unpredictable, and allocating compute power for a specific workload can be quite difficult, and inefficient from a cost perspective. Brigade listens for Cloud Events and manages the pipelines in an Kubernetes cluster, but handling unexpected load is where we introduce Virtual Kubelet — a CNCF project that allows us to schedule Kubernetes pods on virtual nodes, backed by components other than VMs. Virtual Kubelet has multiple providers available, with one of them being Azure Container Instances (ACI) — a service that allows you to schedule and execute containers on Azure’s infrastructure, billed by the second. It turns out that this is a really good match, since Brigade allows you to execute container pipelines, and events often do not require long periods of compute; they can be “bursty.”
How does Brigade work?
Brigade uses a few components to work:
- a controller, which looks for events in a certain namespace.
- a gateway, which translates external events (which can come from a git repo, webhooks, or any other event source).
- optionally, an API to help us interact with CLIs or web frontends.
Then, when an event is fired, the Brigade controller will schedule a worker pod, which executes the JavaScript pipeline of your project, and starts scheduling all the jobs defined.
This is the interesting part — you don’t have to provision infrastructure for the jobs you define — they can be scheduled by Virtual Kubelet on Azure Container Instances, and be billed by the second for the time when your jobs run.
You can have a number of nodes for your regular workloads, and use Brigade with Virtual Kubelet for the event-driven pipelines. You can run as many jobs in parallel as needed, without worrying about provisioning infrastructure, or the cost associated with it.
On top of that, you can use any Kubernetes in any cloud, or on-premises, and scale through Azure when needed.
By the end of this article, we will have a Kubernetes cluster with one actual VM node, a Virtual Kubelet node backed by ACI, and Brigade, configured to schedule jobs on the virtual node.
If you are interested, you can read more about the Brigade architecture in this document.
Configuring Brigade, Virtual Kubelet, and ACI
Here’s a list of the things we are going to need:
- first, you need a Kubernetes cluster — if you don’t already have one, you can get started with a free Azure subscription here, use a Minikube cluster, or any other cloud-hosted Kubernetes cluster.
Note that if you use a Minikube cluster, you won’t be able to create services with public IPs, or publicly exposed ingress objects. You can still follow along, and manually trigger jobs through the Brigade CLI.
- we also need to configure Helm.
- optionally, you can configure an Nginx ingress controller and Cert-Manager to automatically provision TLS ingress objects in your cluster, as described in the Brigade documentation.
- the document above also explains how to deploy Brigade if you configure a cluster with ingress and TLS. If you don’t want to configure an ingress controller, deploying Brigade can be done with Helm:
$ helm repo add brigade https://azure.github.io/brigade-charts
$ helm install brigade/brigade --name brigade --set genericGateway.enabled=true --set genericGateway.service.type=
If you have a cloud-hosted Kubernetes cluster, it should be able to automatically provision LoadBalancer type services with a public IP. If not, you can choose a ClusterIP type service, but keep in mind that this service will not be publicly exposed, and triggering jobs will only be available through the brig CLI, or from inside the cluster.
The setup we are using for this article is the one described in the Brigade documentation that covers configuring ingress objects with TLS. Here’s how the brigade namespace should look:
$ kubectl get deployment,service,ingress --namespace brigade
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
deployment.extensions/brigade-brigade-api 1 1 1 1 62m
deployment.extensions/brigade-brigade-ctrl 1 1 1 1 62m
deployment.extensions/brigade-brigade-generic-gateway 1 1 1 1 62m
deployment.extensions/brigade-kashti 1 1 1 1 62m
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/brigade-brigade-api ClusterIP 10.0.169.168 7745/TCP 62m
service/brigade-brigade-generic-gateway ClusterIP 10.0.0.133 8081/TCP 62m
service/brigade-kashti ClusterIP 10.0.225.37 80/TCP 62m
NAME HOSTS ADDRESS PORTS AGE
ingress.extensions/brigade-brigade-generic-gateway brigade-events-test.kube.radu.sh 80, 443 62m
Note that the subdomain used for provisioning ingress objects is *.kube.radu.sh – if you own a domain, and have access to configuring the DNS for it, you should be able to setup the ingress controller according to the document referenced above.
This ingress endpoint allows Brigade to accept events in the CloudEvents v2 format, a CNCF industry specification which formalizes event schemas used for different systems.
Note that there is another endpoint in the same Brigade gateway which allows arbitrary JSON schema events, so if your system produces other JSON schemas, you can use them without changing the format. See the document about the Brigade generic gateway.
The cluster provisioned for this article is a 1 node AKS cluster:
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
aks-agentpool-35064155-0 Ready agent 19h v1.12.6
$ kubectl top nodes
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
aks-agentpool-35064155-0 1110m 57% 1579Mi 30%
This means we’re only paying for 1 virtual machine node (as the Kubernetes control plane in AKS is free). So how would we schedule tens, or hundreds of jobs on this small, 1 node cluster, which is already at 57% CPU load? We are going to do this using Virtual Kubelet and Azure Container Instances.
For the next part, you will need an Azure subscription which has access to creating Container Instances, as well as access to creating an Azure Service Principal.
If you are running your Kubernetes cluster on AKS, deploying Virtual Kubelet is extremely easy:
$ az aks install-connector --resource-group --name
Keep in mind that your subscription must be able to create container instances – to enable this provider, run az provider register -n Microsoft.ContainerInstance.
Now, if everything worked correctly, we should have a second node in our cluster, virtual-kubelet:
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
aks-agentpool-35064155-0 Ready agent 40h v1.12.6
virtual-kubelet Ready agent 11h v1.13.1-vk-v0.7.4-44-g4f3bd20e-dev
Now that everything is up and running, let’s create a new Brigade project:
$ brig project create
? Project Name testing/brigade-vk
$ brig project list
NAME ID
testing/brigade-vk brigade-f21cf24721ff5303ba21dd5360af71d447d0549b844329206d780c
There are a couple things to note here:
- we are not going to create a CI pipeline, so we are not going to use the clone URL, and we are setting the VCS Sidecar to
NONE.
If you plan to use the Brigade gateway for CloudEvents, you can find more details about it in the Brigade documentation.
Now let’s use the project we just created to test a pipeline. We need a JavaScript pipeline that creates a Brigade job, and schedules it on the virtual-kubelet node we just created:
// save this as brigade.js
const { events, Job } = require('@azure/brigadier')
events.on("exec", (brigadeEvent, project) => {
var hello = new Job("linux-job")
hello.image = "alpine:3.4"
hello.tasks = ["echo Hello Brigade from Azure"]
hello.host.name = "virtual-kubelet"
hello.resourceRequests.cpu = "1"
hello.resourceRequests.memory = "1G"
hello.run()
})
Breaking down the brigade.js file:
- we first import
@azure/brigadierlibrary, which contains all Brigade job definitions. - then, when an
execevent is triggered, we create a new Job, and we run a single task, which echoes a message. - we schedule the job to run on the virtual node we created, and set resource requests for CPU and memory.
- then we run start the job.
Triggering an exec event can be done through the brig CLI, so if your setup doesn’t include public IP services, or ingresses, you can still test this, provided you configured Virtual Kubelet correctly:
$ brig exec testing/brigade-vk -f brigade.js
Event created. Waiting for worker pod named "brigade-worker-01d5c5g11spb27fzjwkjs7gktw".
Build: 01d5c5g11spb27fzjwkjs7gktw, Worker: brigade-worker-01d5c5g11spb27fzjwkjs7gktw
prestart: no dependencies file found
prestart: loading script from /etc/brigade/script
[brigade] brigade-worker version: 0.20.0
[brigade:k8s] Creating secret linux-job-01d5c5g11spb27fzjwkjs7gktw
[brigade:k8s] Creating pod linux-job-01d5c5g11spb27fzjwkjs7gktw
[brigade:k8s] Timeout set at 900000
[brigade:k8s] Pod not yet scheduled
[brigade:k8s] brigade/linux-job-01d5c5g11spb27fzjwkjs7gktw phase Pending
[brigade:k8s] brigade/linux-job-01d5c5g11spb27fzjwkjs7gktw phase Succeeded
done
So let’s see what is happening in our cluster when a job is scheduled:
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
brigade-worker-01d5c58r90v5ernrsy6dkvcf5n 0/1 Completed 0 65s
linux-job-01d5c58r90v5ernrsy6dkvcf5n 0/1 Terminated 0 29s
The pods that we are interested in are:
- the Brigade worker – as we said before, this pod is scheduled whenever an event is triggered, it executes the
brigade.jsfile associated with a project, and creates all the jobs defined. - the
linux-jobpod is our job that was scheduled on the Virtual Kubelet node.
Checking the logs of the job pod:
$ kubectl logs linux-job-01d5c58r90v5ernrsy6dkvcf5n
Hello Brigade from Azure
Since the pod was scheduled on the Virtual Kubelet node, which is backed by Azure Container Instances, we should also see the container created in the Azure portal:

So at this point, we have all pieces put together.
Scaling parallelized jobs with Brigade and Virtual Kubelet
Now let’s assume we have a parallel job that we need to execute – it could be counting utterances of words in a given text, it could be training a machine learning model using a large data set, or any job that can be parallelized.
If we only have a relatively small number of executions (countdown, word count, data set size), the job can be performed sequentially, by a single instance – otherwise, we can parallelize the job, and see vastly improved results.
To keep things simple, for our example, we only need a counter – and see how to parallelize this using multiple Brigade jobs. The container we are going to run as a Brigade job reads two environment variables, COUNTDOWN_FROM, and COUNTDOWN_TO, and starts a loop where it echoes the current count, then sleeps for one second, simulating a process that takes one second to complete.
So let’s say we need to execute the process 200 times – sequentially, it would take 200 seconds, plus the time needed to schedule the pod, pull the image, and start the execution.
In the following pipeline, we will simulate the execution of the process 200 times – in two ways:
- in parallel, by starting 20 Brigade jobs, and splitting the work evenly between the two
- in a sequential job, which does all 200 executions one after the other
Notice how we are using two core Brigade concepts – a Job, and a Group.
const { events, Job, Group } = require('@azure/brigadier')
const parallelism = 20;
events.on("exec", (brigadeEvent, project) => {
// Brigade grouping for jobs
var g = new Group();
for(i = 0; i < parallelism; i++) {
var job = new Job(`parallel-countdown-${i}`);
job.image = "ubuntu";
job.shell = "bash";
job.tasks = [
"for((i=$COUNTDOWN_FROM;i<=$COUNTDOWN_TO;i++)); do echo counting $i; sleep 1; done"
];
job.env = {
COUNTDOWN_FROM: (i * 10).toString(),
COUNTDOWN_TO: (i * 10 + 9).toString()
};
job.host.name = "virtual-kubelet";
job.resourceRequests.cpu = "1";
job.resourceRequests.memory = "1G";
g.add(job);
}
var seq = new Job("sequential-countdown");
seq.image = "ubuntu";
seq.shell = "bash";
seq.tasks = [
"for((i=$COUNTDOWN_FROM;i<=$COUNTDOWN_TO;i++)); do echo counting $i; sleep 1; done"
];
seq.env = {
COUNTDOWN_FROM: (0).toString(),
COUNTDOWN_TO: (199).toString()
};
seq.host.name = "virtual-kubelet";
seq.resourceRequests.cpu = "1";
seq.resourceRequests.memory = "1G";
g.add(seq);
// runAll runs all jobs in parallel
g.runAll();
});
In this scenario, we only start the jobs – however, with Brigade, we can get the result of the execution, and take different actions based on it.
After we run this pipeline with brig, we can see both the parallel jobs, and the sequential one starting at around the same time – then, the parralel jobs start finishing, and the sequential one takes around 3 minutes longer to finish.
The tool used to visualize the pipeline is Brigadeterm, which can also be used to get the job logs.
There is currently a known bug which marks job duration wrong.
Brigade also comes with a web dashboard – you can access it by executing brig dashboard(and, if deployed in a different namespace, by passing the --namespace flag). We can also see the difference between the parallel and sequential execution:
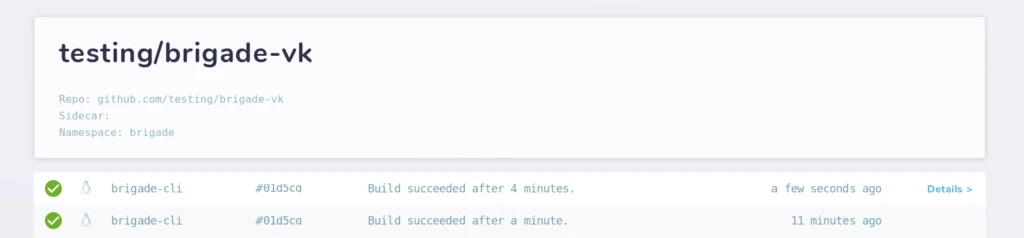
Keep in mind that we have a 1 node cluster, and all jobs are scheduled on top of Azure Container Instances, allowing us to only pay for the few tens of seconds our jobs are running.
By default, Azure Container Instances have a quota of 100 container groups per subscription – if you need more, a simple request with Azure Support can help. For more information, see azure-quotas.
In this example, we are using an ubuntu container, with a few commands – keep in mind that you can use any container to run Brigade jobs, and you can run any command that is available inside that container.
Now that we have everything working, we can programmatically call the Brigade endpoint we configured with TLS and have our brigade.js file handle the event, executing our pipeline.
Thebrigade.js file will have access to the incoming event, as well as to the project information (notice the brigadeEvent and project objects in the event handler).
At this point, you can use the /cloudevents/v02/project-id/secret endpoint in the Brigade gateway we just exposed to send POST requests in the CloudEvents format:
{
"specversion" : "0.2",
"type" : "your.custom.event.type",
"source" : "event source",
"id" : "A234-1234-1234",
"time" : "2018-04-05T17:31:00Z",
"contenttype" : "json",
"data" : {}
}
Get started with Brigade
Here are the best places to get involved with Brigade and the community:
- the Brigade GitHub repository
- the official documentation
- the #brigade channel in the Kubernetes Slack
- participate in the weekly community Brigade community meeting, Tuesdays at 9:30AM PST
We’re always happy to help if you have questions, and we’d love to see what you build with Brigade!








