

What’s new with Microsoft in open-source and Kubernetes at KubeCon North America 2025
From improving reliability and performance to advancing security and AI-native workloads, our goal remains the same: make Kubernetes better for everyone.

Earlier this year, we released Data Accelerator for Apache Spark as open source to simplify working with streaming big data for business insight discovery. Data Accelerator is tailored to help you get started quickly, whether you’re new to big data, writing complex processing in SQL, or working with custom Scala or Azure functions. After years of optimizing its speed and performance for our enterprise-scale demands, we continue to rely upon its internal deployments today to deliver best-in-class products loved by millions of customers.
Today we’re announcing our Data Accelerator v1.2 release, including these updates:
This has been one of our top feature requests! Now, Data Accelerator Flows can be run as jobs on an Azure Databricks cluster.
Azure Databricks enables data exploration and collaboration across data engineers, data scientists, and business analysts. Performance and reliability configurations handle the heavy lifting to minimize time spent monitoring clusters, while dynamic cluster management behind-the-scenes helps to reduce costs.
After kicking off a Data Accelerator environment targeting Azure Databricks, head over to the Azure Databricks workspace for deep learning and great features like real-time interactive Notebooks or dynamic reporting.
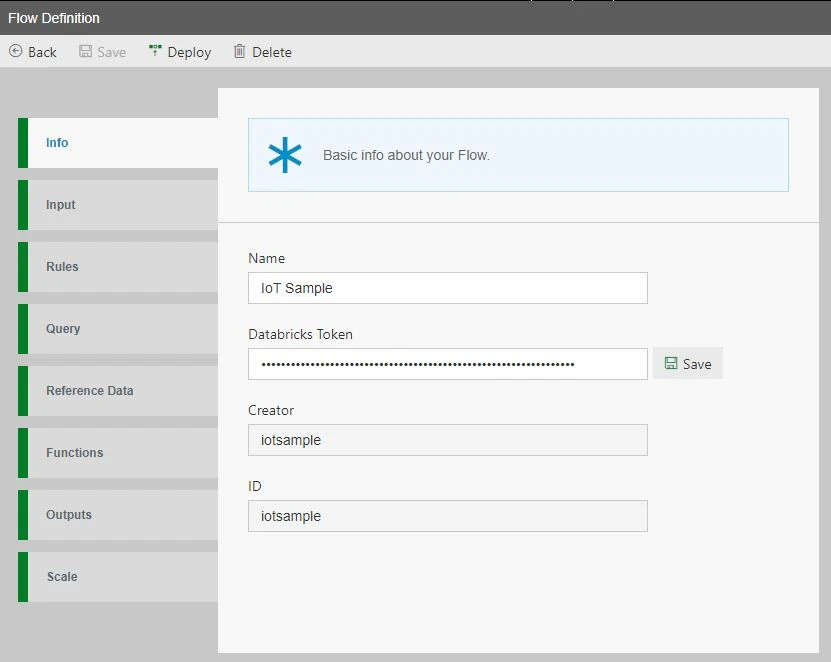
Next up is the addition of Azure SQL Database output. We’re pleased to include this popular storage option for scalable, intelligent, cloud-based SQL. In addition to broad SQL compatibility, Azure SQL Database includes great features such as data synchronization across multiple databases or instances, automation of repetitive tasks using SQL Agent, temporal tables to track the full history of changes to your database, and in-memory technologies to improve performance and potentially reduce cost.
Azure SQL Database is an excellent choice for streamlining on-premises migrations and connecting data pipelines directly to a fully managed data warehouse experience.

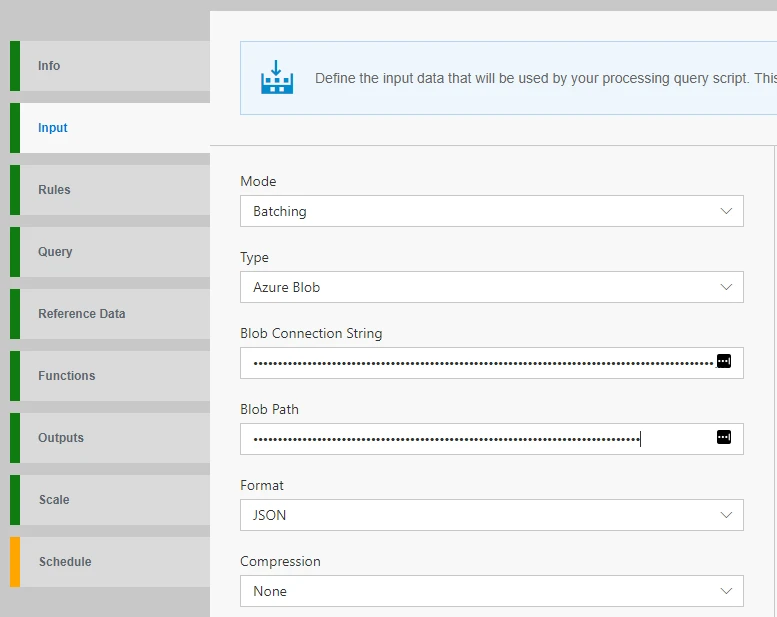
Lastly, this release adds first-class support for batch processing in Data Accelerator, enabling you to develop and manage batch and stream processing in the same infrastructure.
After configuring the input source, use Data Accelerator’s built-in Schema Inference feature to sample the data and handle the Flow’s schema. Today’s experience supports Microsoft’s cloud object storage, Azure Blobs, as the input type. Then tell the job scheduler whether it’s a one-time or recurring job and specify any delay and windowing preferences.
Whether you’re just getting started on an Apache Spark-based big data journey or evaluating solutions for your team’s needs, check out the tutorials to take Data Accelerator on a quick test drive and let us know what you think! For feedback, feature requests, or to report a bug, please file an issue. We’re quick to reply and look forward to hearing from our community!
We continue to listen to requests from our internal and external customers, which is what informs this latest wave of investments. You can look forward to more features and functionality in the coming months. For future releases, we’re working on adding telemetry, logging, and documentation to help diagnose and mitigate pipeline issues.
You can keep up with the latest developments by following our GitHub repository for updates.
General questions or feedback? Let us know in the comments below.
From improving reliability and performance to advancing security and AI-native workloads, our goal remains the same: make Kubernetes better for everyone.

DocumentDB Kubernetes Operator enables you to deploy and manage open-source DocumentDB on Kubernetes. Simplify cloud-native database operations today.

The next major release of Azure Container Storage delivers higher IOPS and less latency compared to previous versions.

We'll create an independent identity for DocumentDB and provide a conduit for database providers to contribute to our mission.