



Following the release of our Developer Preview in June, today we’re announcing an exciting next step as we make the source code of TensorFlow-DirectML, an extension of TensorFlow on Windows, available to the public as an open-source project on GitHub. TensorFlow-DirectML broadens the reach of TensorFlow beyond its traditional Graphics Processing Unit (GPU) support, by enabling high-performance training and inferencing of machine learning models on any Windows devices with a DirectX 12-capable GPU through DirectML, a hardware accelerated deep learning API on Windows. TensorFlow-DirectML works on both native Win32 and on Windows Subsystem for Linux (WSL). Students, beginners, and enthusiasts can utilize any DirectX 12 GPU in their machines to accelerate model training and prediction. Check out our new tensorflow-directml repo on GitHub.
TensorFlow with DirectML on GitHub
TensorFlow is a widely used machine learning framework for developing, training, and distributing machine learning models. Machine learning workloads often involve tremendous amounts of computation, especially when training models. Dedicated hardware such as the GPU is often used to accelerate these workloads. TensorFlow can leverage both Central Processing Units (CPUs) and GPUs, but its GPU acceleration is limited to vendor-specific platforms that vary in support for Windows and across its users’ diverse range of hardware. Bringing the full machine learning training capability to Windows, on any GPU, has been a popular request from the Windows developer community.
The DirectX platform in Windows has been accelerating games and compute applications on Windows for decades. DirectML extends this platform by providing high-performance implementations of mathematical operations—the building blocks of machine learning—that run on any DirectX 12-capable GPU. We’re bringing high-performance training and inferencing on the breadth of Windows hardware by leveraging DirectML in the TensorFlow framework. Not only does this extend TensorFlow’s GPU reach on Windows, but it also applies to the Windows Subsystem for Linux (WSL). Users can run or train their TensorFlow models in either a Windows or WSL environment with any DirectX 12 GPU.
In June, we released the first preview of tensorflow-directml, our fork of TensorFlow that runs with a DirectML backend. Today, we are moving our development of tensorflow-directml to GitHub so we can engage with the TensorFlow community and focus our efforts on the issues users care about most.
TensorFlow with DirectML Backend
The DirectML backend is integrated with TensorFlow by introducing a new device, named “DML” instead of “GPU”, with its own set of kernels that are built on top of DirectML APIs instead of Eigen source code as with the existing CPU and GPU kernels.
DirectML is a low-level library built on top of Direct3D 12; the API is designed for high-performance, low-latency applications that require absolute control over resource allocation, and work scheduling. Integrating DirectML with TensorFlow involves a device runtime that’s responsible for managing device memory, copying tensors to and from the host, recording GPU commands, and scheduling and synchronizing work that occurs on both host/CPU and device timelines. Some of the key components of this device runtime and how it interfaces with the DirectX platform, are shown in this figure below:
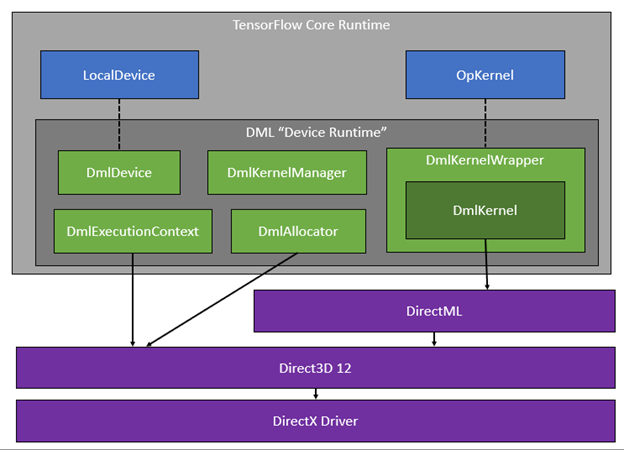
- DmlDevice : Implements TensorFlow’s “Device” class and ultimately manages all device-related functionality.
- DmlKernelWrapper : Implements TensorFlow’s “OpKernel” interface, which allows device-specific implementations of operators.
- DmlKernel : Provides a concrete implementation of a TF operator by calling into DirectML.
- DmlKernelManager : Caches DmlKernel instances to avoid recompiling DirectML operators when possible.
- DmlAllocator : Manages GPU buffers backing TensorFlow tensors.
- DmlExecutionContext : Schedules work on the GPU, such as executing operators or copying memory.
Stay Involved
Check out our new tensorflow-directml repo on GitHub. We’re listening to feedback and open to contributions from community members looking to accelerate the capabilities as we progress on our journey to integrate our fork with the official build of TensorFlow in the future.
If you haven’t already given the tensorflow-directml package a try, follow the getting started documentation for setup on native Windows or within WSL. It is as simple as getting your python environment setup up and then running pip install tensorflow-directml. We look forward to hearing your thoughts in the tensorflow-directml repo.








